
tg-me.com/ds_interview_lib/857
Create:
Last Update:
Last Update:
Почему перемешивание данных может сломать модель
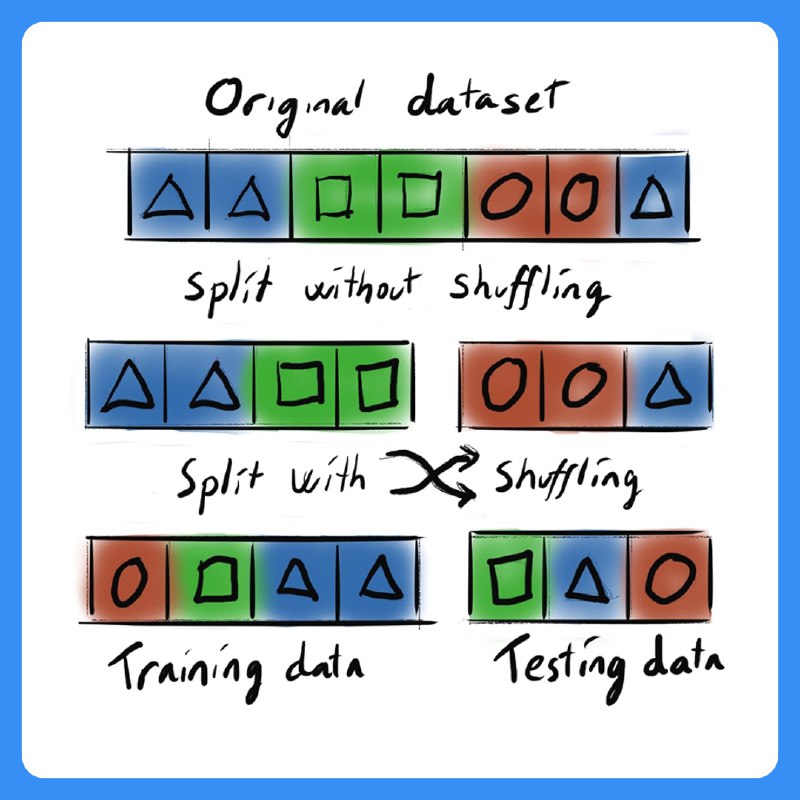
В машинном обучении перемешивание (shuffling) данных перед обучением модели часто считается хорошей практикой. Но в некоторых случаях это может привести к неожиданным ошибкам и ухудшению качества модели.
❗ Временные ряды → Если модель предсказывает будущее, перемешивание разрушит временную структуру. Решение: использовать time-based split.
❗ Группированные данные → Например, если данные по одному пользователю оказываются в train и test, это приведёт к утечке данных. Решение: делать групповую валидацию.
❗Последовательные зависимости → В задачах NLP или рекомендательных систем порядок данных может быть критичен.
BY Библиотека собеса по Data Science | вопросы с собеседований
Share with your friend now:
tg-me.com/ds_interview_lib/857